
Businesses are constantly seeking innovative ways to leverage artificial intelligence. In this three-part blog post series, we will examine three methods by which companies can utilize AI to:
- Reduce the time required for teams to locate relevant information.
- Address knowledge fragmentation within large organizations and offer a unified platform for accessing all company knowledge.
- Automate repetitive tasks performed by knowledge workers.
Introduction
Large Language Models (LLM) have revolutionized how we work with unstructured data. Their capacity to understand and generate text at a superhuman level enables a vast number of new use cases and finally makes it possible to solve problems that have held ideas back for decades.
One such idea is Knowledge-based Systems, which are intelligent reasoning systems that can be used with natural language to solve complex problems based on structured and unstructured data. Although they were imagined in the 1980s, I argue that only the recent developments of LLMs finally make it possible to actually build working knowledge-based systems.
AI is much more than Large Language Models and the current hype around chat systems. For a historical perspective on AI, I recommend having a look at Schmidhubers History of Modern AI and Deep Learning and for a general Introduction to the different areas of Artificial Intelligence, the following Comprehensive Overview of AI.
In this article, I will summarize two years of experience building LLM-powered knowledge-based systems, ranging from simple Question Answering Systems implemented as Retrieval Augmented Generation (RAG) workflows to AI Agent platforms that enable the automation of complex multi-step business processes. I will then look at the current and future applications of AI Agents.
This article is split into three parts, each published separately, to support understanding and provide sufficient space to cover the different knowledge-based systems in detail.
The first part will describe Question / Answering Systems, the second Knowledge Management Systems, and the last part will explain AI Agent Platforms.
Each part will focus on discussing the purpose of the system, how it differs from the previous one and challenges and recommendations on building and deploying it.
But first, let us define Knowledge-based systems.
Knowledge-based systems
Knowledge-based Systems (KBS) have been developed as a sub field of Artificial Intelligence since the early 1980s. The main components of a KBS is a knowledge base that contains information and facts, and a reasoning engine that is able to derive new knowledge and perform cognitive tasks, like problem solving, based on information contained in the knowledge base.
KBS where originally build to support problem solving in very narrow domains like medical diagnoses or protein structure analysis, through the use of rules managed by experts. In the 1990s their application was extended to perform meta-learning and to incorporate unstructured data to enable automatic reasoning.
To make things clear, a KBS is more than a traditional database. Where a database is used to store information that can be retrieved afterward, all the reasoning is happening outside of the system, either by a user or a system using the database. A KBS, on the other side, has the "intelligence" to understand the data that it stores and is able to reason about it. In the case of a DB, a user has to clearly understand the structure of the data in order to formulate a query; a KBS is able to answer partially undefined questions and draw conclusions from the data on its own.
KBS are, therefore, a type of intelligent database that are able to provide answers in natural language and reason about its data.
I argue, that before the rise of LLMs, we did not have the capacity to work with unstructured data and to perform automatic reasoning in a domain agnostic way.
LLMs are the key invention that therefor enables the development of KBS systems that can understand and reason over a vast corpus of knowledge. In form of AI Agents, they can be used to solve pre-defined business tasks to accelerate knowledge workers.
In this article, we will look at three tiers of KBS that build on top of each other with increasing complexity and capabilities, but that serve different use cases:
- Tier I – Question Answering Systems: Support Information retrieval for an individual or a small team on a single corpus of knowledge.
- Tier II – Enterprise Knowledge Systems: Counter the fragmentation of information in an organization by enabling access to all knowledge within an organization from a single system.
- Tier III – AI Agent platforms: Accelerate the work of knowledge workers by automating individual business processes.
Next, we look at each of them in detail, discussing their capabilities and challenges when implementing and maintaining such systems.
Tier I – Question Answering Systems
The purpose of Question Answering Systems (QA) is to provide a small group of people a way to easily ask questions about a limited corpus of knowledge through natural language.
Although question-answering systems have a vast history and the earliest systems, like Baseball, date back to 1961, in this article, I want to focus on Retrieval Augmented Generation (RAG) systems that got popular after 2020.
Figure 1 illustrates such a RAG system that is able to Import Documents in varying formats and types (1) and performs pre-processing and storage in a database (2). Users are able to ask questions in natural language through a chat interface (3). The information retrieval component of the system identifies for a question all relevant text fragments (4) and leverages an LLM to generate responses (6) that are returned to the user in the form of answers in natural language (6).
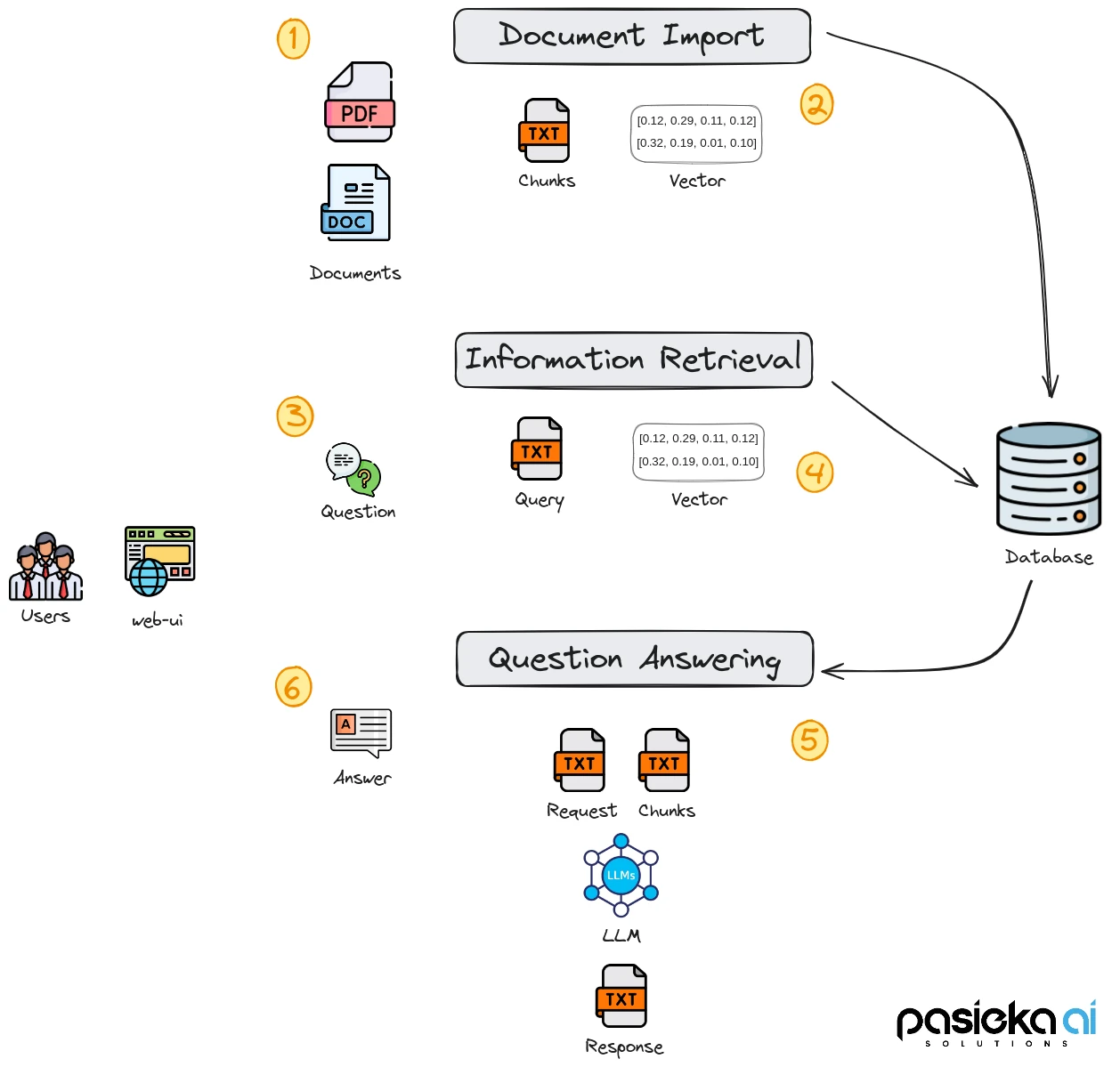
Challenges building and maintaining a Q/A System
RAG Systems have come a long way since 2020 and are today the de-facto standard way how to build Question Answering Systems.
A lot has been written on how to build RAG systems (have a look here and here), and there are many facets to building a high performing RAG system, from the data pre-processing that focuses on information representation and semantic chunking (see this reference), to hybrid search that combines keyword search and dense retrieval, re-ranking and other techniques (see this post), to select only relevant document fragments.
This being said, building your own RAG has been made significantly easier through excellent open source libraries like LLamdaIndex or LangChain that make it possible to deploy a RAG system in a few lines of python code.
Recommendations for Implementing a Q/A System
If your use case is limited to providing a Q/A system to a single team, based on a limited number of documents in standard formats (like pdf, Word, HTML, …) there are even open source solutions that work out of the box and that can be deployed as simple docker containers, like RAGFlow or Onyx (former Danswer).
Such a Q/A system can be deployed easily, making use of either local inference servers like Ollama in case of security concerns and offline use cases or cloud deployed LLMs in your own hyperscaler subscription (i.e. AWS, Azure, GCP) or LLM provider service (OpenAI, Anthropic or Aleph Alpha).
How to get started with Q/A Systems
The fastest way to get experience with Q/A Systems is to try out one of the available web demos, either
from RAGFlow or from Onyx.
At the time of this writing, the RAGFlow web demo is fully operational and demonstrates, the capabilities of the system, but is very slow in processing documents and the default deepseek models can run into out of quota errors. For those with a little bit of develop experience, I therefor recommend to try the RAGFlow Docker Build and run an instance of RAGFlow on their local machine.
My recommendation is to do the following.
- create a small knowledge base and populate it with a few PDFs that you know well.
- in the case of RAGFlow, create a Chat Assistant and ask it about the content of the PDFs.
- Experiment with different questions that need information from parts of the documents like Tables and images. Ask questions that require the system to combine information from different documents.
- Change the Assistants system prompt and see what effect it has on the quality of the generated answers.
Doing so will provide you with essential experience about the capabilities and limits of a Q/A system.
Where Q/A Systems fail
The Limitations of Q/A systems are their scale with respect to the size of the organization and the knowledge corpus that they can work with.
In addition, be aware that most Q/A systems poorly support data access policies. In most cases, documents are copied and imported into the system, providing access to all data for all users.
If your use case involves a complete organization and has to take into account (as it should) aspects of data security to incorporate varying data sources like Sharepoint, Confluence, Network shares or Email, then I recommend to have a look at Type II – Enterprise Knowledge Systems.
Key Takeaways for Question / Answering Systems
- Deploy existing solutions instead of building your own.
- Be aware of the limitations of a deployed solution with respect to data access policies, number of documents, knowledge domains and the number of users.
- Don’t try to import complete document platforms. Use an Enterprise Knowledge System instead.
Thank you for reading, I hope you found it useful. In the next post we will look at Enterprise Knowledge Systems that give an organization a chance to counter the fragmentation of information by building a portal through which users can access all knowledge anywhere in the organization.
Still here? Then you will love Part 2.