
Hello, and welcome back to this three-part series on Knowledge-Based Systems. In the first part, we introduced Knowledge-based Systems and described Question Answering (Q/A) Systems that can help an individual or a group to access information about a limited domain.
Although this use-case is served well with Q/A Systems, it does not scale to an organization as a whole. Every bigger organization is struggling with the fragmentation of information over multiple platforms, media and formats.
Research shows that modern knowledge workers spend up to half a day per week searching for information. Remote work and the ever increasing number of different communication platforms, only add to the problem.
In this second Post, we will look at Enterprise Knowledge Systems, that can help organizations counter this trend and enable them to provide their employees a single portal to access all information they need, quickly.
Tier II – Enterprise Knowledge Systems
So far, we looked at Question Answering Systems for a limited domain using a common RAG workflow. Such a system is a good solution for use cases, where one wants to support the research work of an individual or a small team.
What we want to look at now, are Enterprise Knowledge Systems (EKS) that accelerate the information access and its use throughout a complete organisation and even its customers. Figure 2 illustrates such a system, highlighting its difference to Question Answering Systems.
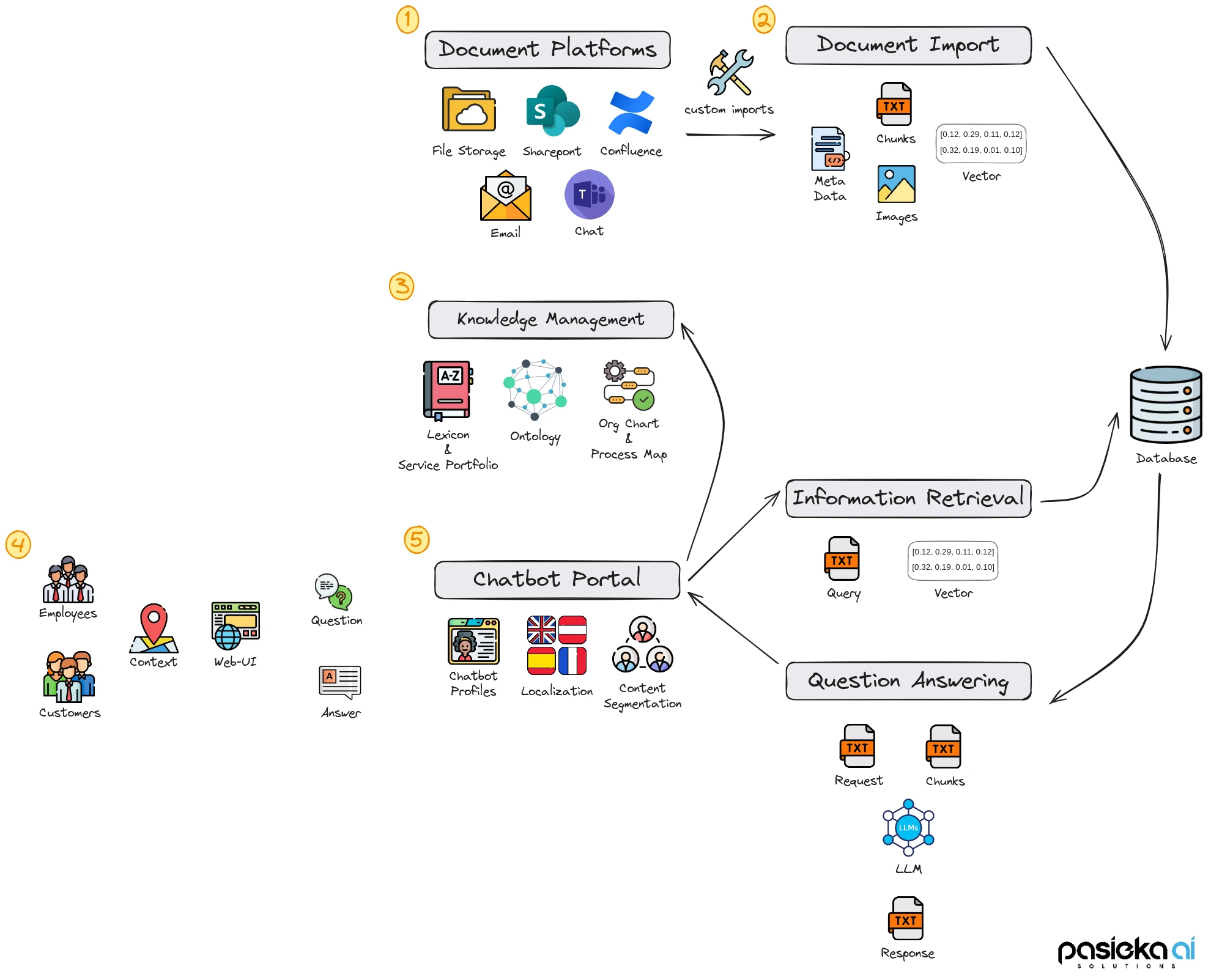
The biggest difference compared to Q/A systems, is the scale and diversity of the information that is ingested by the system. Instead of individual documents, complete document platforms (1), like Confluence, Sharepoint, File Storage, or Email and Chat are being imported. This will, in most cases, require custom import processes (2) that not only support custom file formats and different modalities but, most importantly, provide metadata about the imported documents. This metadata is stored alongside the information extracted from documents (chunks and embedding vectors) and is vital during information retrieval. It enables the enforcement of data access policies and increases the accuracy of information retrieval by enabling more precise searches for relevant documents.
Importing a vast amount of information from different document platforms, creates a document corpus, that is not only huge in size, but in diversity of its content. When dealing with such a big and heterogeneous document corpus of overlapping domains and vocabulary, information retrieval becomes a challenge. One way to cope with this challenge is to perform explicit Knowledge Management (3) that tries to provide up-to-date information about the organization itself and its particularities. This includes information about company wording, products and services, org charts, and, in the best case, an ontology, which is a formal representation of knowledge within the different domains, describing the relationship between concepts and entities. This organizational information can be used during the import of documents to enrich the metadata, as well as during the information retrieval to filter candidate documents. An ontology helps the system understand relationships between concepts, and a service portfolio allows for answering questions that connect documents to specific services and products.
While keeping the user interface to chat, similar to Q/A Systems, the information retrieval in EKS can be supported by including information about the User and her context (4) into queries. For example, in case of an employee, her position within the organisation and in particular their role can be taken into account in order to rank possible documents differently, or tailor the generated answers to their profile.
All those efforts culminate in building a Chatbot Portal (5) that serves internal and external users as a single point of entry to access contextualized information from anywhere within the organization. Different audiences can be served by customized Chatbot Profiles that are implemented with RAG workflows that are backed by different data sources and system configurations (i.e. system prompts, personas and instructions). Based on the user context, the interaction with the system can be localized and content segmented in a way to reflect existing organizational structures.
Example: How an Enterprise Knowledge System accelerates research
To give a concrete example, imagine a multi-national construction company that utilized a Knowledge Management System to support their employees.
Shiva, a french labour law expert, needs to create a report on ongoing construction projects in Germany. She utilizes the dedicated Project Inquiry Chatbot to get a description of all ongoing projects in Germany and details about them.
The EKS is able to ensure that Shiva only receives information that she is entitled to, excluding, for example, budget and financial information. The system is not only able to base its answer on source documents in different languages but also will leverage the company service portfolio and org chart. It will answer questions about the different services offered as part of the projects and the responsible project owners.
As a follow-up, she takes the list of project owners and uses another Chatbot, focused on Email and Chat conversations, to get a summary of previous conversations that she had with the different project owners and with whom she has not been in contact before.
Because she knows how her German colleagues appreciate an email in German, she uses the chatbot to formulate a personalized email for each new contact that explains her intent and the support she needs from them based on the particular project.
The EKS is able to assist Shiva because it has ingested information from different source systems, like project reports from SharePoint and Emails. The EKS is able to relate service and product names and answer questions about them that are mentioned in project reports with product documentation that is described in the EKS Service Portfolio. The organizational chart helps to identify the project owners and their means of contact, which enables the Email Bot to identify relevant previous conversations.
Challenges with building and maintaining an EKS
An Enterprise Knowledge System is a powerful tool to accelerate a companies knowledge workers, but is not without its own challenges. Compared to RAG based Question Answering Systems, there are no out of the box solutions that one can deploy easily. The real benefit of a EKS depends on its deep integration with existing knowledge systems and documentation. It requires significant configuration, customization and maintenance work.
The biggest challenges include the following topics.
- Data Quality: Unsurprisingly, the quality of the input data and the way it is ingested by the system is essential to providing value. Similar to traditional challenges of Enterprise Search, an EKS will have difficulties finding relevant information in cases where there are outdated duplicates of documents. An EKS can support data hygiene by highlighting similar documents but will rely on manual review and heuristics to avoid data duplication.
- Content Segmentation: The information retrieval over a big corpus remains the key challenge for an EKS. As part of Knowledge Management, information retrieval can be improved by segmenting the document corpus and reducing the candidate space for individual requests. This can happen explicitly by providing the User an option to filter source systems or domains that are being taken into account, or implicitly by taking the User’s context (i.e., role in an organization, previous requests, …) and intent into account. If an ontology exists that describes the different domains within an EKS, documents during ingestion can be tagged based on their content. This metadata about a document can then be used to filter during information retrieval based on the user’s intent.
- Knowledge Management: As described in the overview, the Knowledge Management aspect of an EKS helps the system to improve its Information Retrieval and the quality of the generated answers. This comes at the cost of resources that need to be invested to build and maintain the knowledge support structures. In addition, there is the organizational question of who has the right and the responsibility to maintain what part of the knowledge management system.
- Continuously Increasing Request Complexity: With an increasing data corpus and a number of different Chatbot Profiles, the use cases and the number of edge cases increase. Requests tend to become more complex as users discover new possibilities to leverage the system for their needs. This includes chained multi-part questions, requests for information across multiple different source systems and modalities, or long conversations with increasing dependency on per-conversation context. Other requests can require temporal reasoning over information from a specific time period, or questions that necessitate understanding implicit relationships across documents. As a result, the system needs continuous development and tuning, ranging from more advanced data extraction and pre-processing methods like Visual Language Models that improve the extraction of structured data from unstructured source documents to the continuous tuning of system prompts and agent profiles.
- Data access: The added value of an EKS is proportional to the data it has access to. Big organizations have the challenge of spreading information across many platforms and technologies. Providing data access to the varying platforms can be an organizational challenge, mainly because the established data access permissions have to be kept intact. An EKS is a Chief Information Officer’s (CIO) dream and nightmare in one. Ensuring that information ingested by the EKS is only available with the appropriate permissions is essential. An additional factor is the freshness of data available through the EKS. Depending on the size of Document platforms and their technical capabilities, there might be a significant delay between the creation of information in a source system and until it is available in the EKS.
- ML Cybersecurity (MLSEC): As described about the challenges of Data access, an EKS is a particularly interesting target for attackers, as a compromise of a centralized system of this kind allows access to a huge amount of sensitive information. Besides traditional cybersecurity concerns, a EKS is susceptible to machine learning security issues like data poisoning and in particular indirect prompt injection (see this post), an attack vector that uses specially crafted documents that contain Jailbreak instructions for an LLM, manipulating the answers generated by the system in security compromising ways. An overview of LLM-specific cybersecurity threads can be found as part of the OWASP Top 10 LLM risks.
- Content moderation: Lastly, when providing customers and external partners access to specific public-facing Chatbots, organizations start to care about moderating the answers generated by the EKS. Unfortunately, making sure answers align with the organization’s political and ethical guidelines, similar to Jailbreak, is an unsolved problem. Providing a tailored system prompt and Chatbot profile can go a long way to nudge the system to behave, but one should always be aware that maliciously crafted user input can cause the system to generate answers that do not align with an organization content policy. Models hosted by LLM service providers or cloud services like OpenAI, Anthropic, Azure, AWS, and GCP either have configurable content filters in place or provide moderation models that one can use to classify user or model-generated content. For custom solutions, one can build on projects like deepval, guardrails.ai or Nvidia – NeMo Guardrails.
Recommendations for Implementing an EKS
There are a limited number of commercial EKS systems available, like Guru or Squirro but as described previously, the value of an EKS is proportional to its integration and adaptation to an organization. Organizations have therefor the challenge to decide if they either invest in using a commercial EKS system and configure it to their demands, or invest in building their own solution.
Organizations that can invest in supporting a development team of 5-7 people can expect to get returns on their investment within 12-18 months and to be able to experiment with prototypes significantly earlier. Specially companies that already develop software that can benefit from text analysis, understanding and generation should evaluate to invest in building their own solution that serves to accelerate internal use cases, but can be the stepping stone to extending existing products and services, or develop new ones.
The following recommendations will hopefully be useful for such projects:
- Split System Evaluation: During development, but also during operation of the EKS, evaluate Information Retrieval and its Question Answering separately. Separating the two makes it easier to automatically evaluate changes to the system as well as to detect drift in performance during operation. The evaluation of Information Retrieval can be automatized by Mean reciprocal rank (MRR) scoring of test data in data corpora of different size. Question-answering performance can be evaluated by comparing generated answers with ground truth answers using LLMs.
- No single model to rule them all: Plan from the beginning to be able to switch models rapidly, not only to be able to leverage the newest foundation models but also to benefit from the increasing performance of open-source small language models. Enable the use of different models for varying stages of the input processing and answer generation and evaluation. Using a small but specialized model for information extraction like olmOCR, Docling or API solutions like Mistral OCR can improve data quality significantly while keeping data processing costs and time low. Using different LLMs for the varying steps in Answer Generation, like answer ranking, groundedness, and relevance checks, can also reduce costs and latency.
- Beyond Python: An EKS is a complex system with only small parts of it that require a deep understanding of NLP and LLMs. If your organization has experienced developers in system languages like Java, GO or Rust, build as much of the system in those languages and keep the python development to core components like data extraction and knowledge representation. More about this in another blog post of mine: Blog: The Pain of hiring Python AI Engineers
How to get started with commercial EKS
Getting hands on experience with EKS systems is not as easy as with Q/A Systems. Because they focus on Enterprise integration and wide spread use within an organization, a simple web demo is insufficient.
I therefor recommend to book a demo with the corresponding vendor. All the bigger ones like Squirro or Guru are happy to do so.
When booking a demo and during it, make sure to ask about the following
- customized demos for your industry and organization size
- supported for data sources that are relevant for you and how correct access control to documents is enforced
- if the information that you care about can be extracted from sources, like for example structured data, images, over multiple documents, …
- What customization options exist that relate to data ingestion, chat agents and system behavior as a whole.
- deployment options (cloud only, on-prem or hybrid)
After having seen 2-3 such demos, you will have a good picture of the current capabilities of Enterprise Knowledge Systems and can decide for yourself if you can buy and configure an existing solution, or if you better build your own.
Where EKS fail
EKS still "only" support knowledge workers to find information faster and help with generating short texts and documents.
They are the wrong tool when trying to automatize multi-step reasoning tasks or use them through non-chat-based interfaces.
For solving those tasks, one needs a more agentic approach, which lead us to the third and final type of knowledge-based systems, the AI Agent platforms.
Key Takeaways for Knowledge Management Systems
- The value a EKS provides depends on its integration with existing document platforms.
- When building your own solution, be aware of the size of the project and the unresolved challenges.
- Don’t try to use EKS for process automation. Use an AI Agent Platform instead.
Thank you for reading, I hope you found it helpful. In the next post, we will look at AI Agent platforms that accelerate the work of knowledge workers by using AI agents to automatize pre-defined workflows.
Don’t stop here and continue with the third part.